
Introduction to AI
We want to discover instances of form in The Cantos. The manual discovery of form given 800 pages of complex poetry is impractical. Instead we can levy the mathematical nature of form by first attempting to convert The Cantos to number and then identifying form in a numeric sequence (a more trivial task). However converting text to number is not easy. Traditional algorithms have failed to work with language, since language is not logical. AI, however, is capable. AI models are trained by example, as are we.
This is not the AI of rumours. This is a very simple example of the type of AI that measures tweets and reviews for sentiment; a process known as text classification. A basic model, like BERT, has two classes, POSITIVE and NEGATIVE, and will score a piece of text against those classes (or labels).
A score of 0 means the text does not belong to that class. 1 means it does.
We can easily use a BERT model from the AI model hub Hugging Face. From there we can input some text and have it scored. To access the model we write:
model_name = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModelForSequenceClassification.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
This provides us with a classifier which we can then pass a piece of text to. All we have to do is run the classifier on a line of a Canto, for example:
classifier("And then went down to the ship,")
We get an output that looks like this:
{
"label": "POSITIVE",
"score": 0.7809377908706665
},
{
"label": "NEGATIVE",
"score": 0.2190622091293335
}
We have converted text to number by measuring how well the text belongs to two classes, positive and negative. When we pass the whole of Canto I to this model we get the following graph:
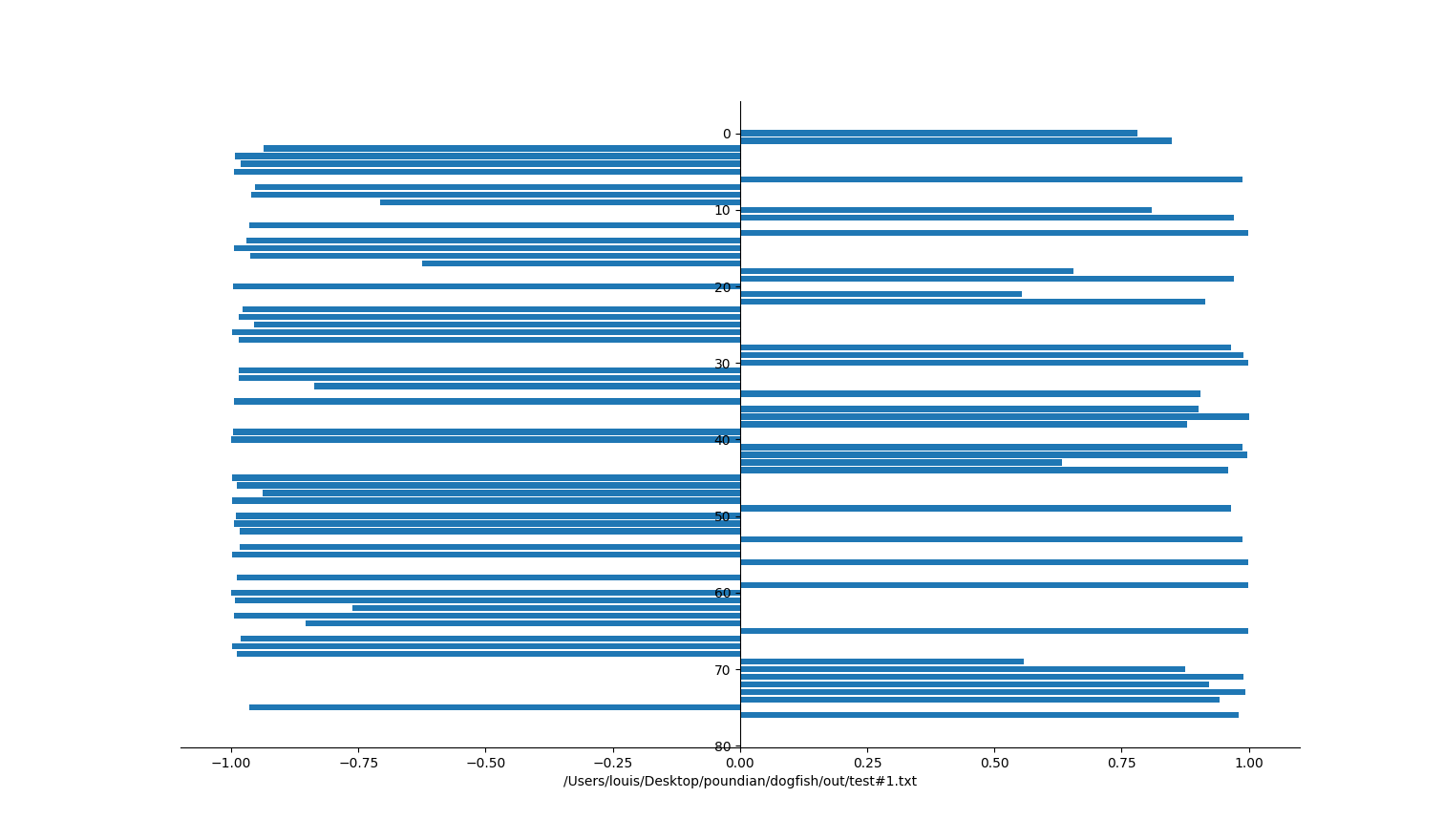
(Lower scoring value discarded)
I found it insightful to look at a Canto in another dimension, but we don’t know what we are looking for, nor if what we are looking at is at all accurate. What we need is a good example of form to compare our readings to.
The Eleusinian Rites
As mentioned in Fugue and Fresco, the Eleusinian Rites are identified in Davis as a “dark/light motion” which can be found throughout The Cantos. But the Eleusinian Rites Davis discusses in Chapter 1 are different. They are more closely tied to the rebirth myth of Persephone, her descent into Hades and eventual alighting. The problem is that Pound used them as fugal in a letter to his father in 1929:
A. A. Live man goes down into world of dead ...
C. B. ‘The repeat in history’ ...
B. C. The ‘magic moment’ or moment of metamorphosis, bust through from quotidien into ‘divine or permanent world.’ Gods, etc.
This structure still causes confusion. It is nice in that it draws in Homer, Ovid, and Dante (or the later Schifanoia Triumphs). Davis talks about this structure lying across Cantos I and II.
In Canto I, Odysseus descends into the world of the dead. At the end of Canto I, Pound realights from the world of the dead, setting down his translation of Homer. Canto II starts with Proença, medieval Provence, a birthing nation and poetic revival. Then a return to the ship, this time from Ovid, which begins to metamorphose into an island, with Dionysean imagery, vineyards and lynxes (also reminiscent of the Schifanoia Triumphs). The bust comes close to an orgasm and is followed by stillness and reminiscence. (The Eleusinian Rites are also performed in praise to Aphrodite.)
That is a simple trace — the nesting, repetitions and arrangement of dark and light (or dromena and epopte) are far more complex. I couldn’t tell you whether this is fugal, but it is certainly not the simple dark/light motion we see elsewhere. In Chapter 2 Davis identifies stanzas of dromena (loss, confusion, evils) and epopte (pro-art, knowledge and enlightenment). But this is still too difficult to get us started. What follows is another form of the Eleusinian Rites that is not as complicated as the fugal E.R. and not as subjective as the dark/light motion.
Both Kay Davis and a book he works from, Leon Surrette’s A Light From Eleusis, quote Plutarch who says this about this Eleusinian Rites:
... chance directions, difficult detours, disquieting and endless walks through the darkness. Then, before the end, complete terror; one is overcome by shivering, trembling and breaks out into a cold sweat. But then a marvellous light bursts before one’s eyes, and one walks in pure meadows where voices echo and figures dance. Sacred words and divine apparitions inspire a religious respect. At that time, the man, from then perfect and initiated, becomes free and holy and moving about without restraint celebrates the Mysteries, a crown on his head. He lives with pure and holy men, and sees on earth the crowd of those who are not initiated and purified crush and jostle themselves in the mud and darkness, and because of fear of death, remain among evils from failure to believe in the joy of the beyond.
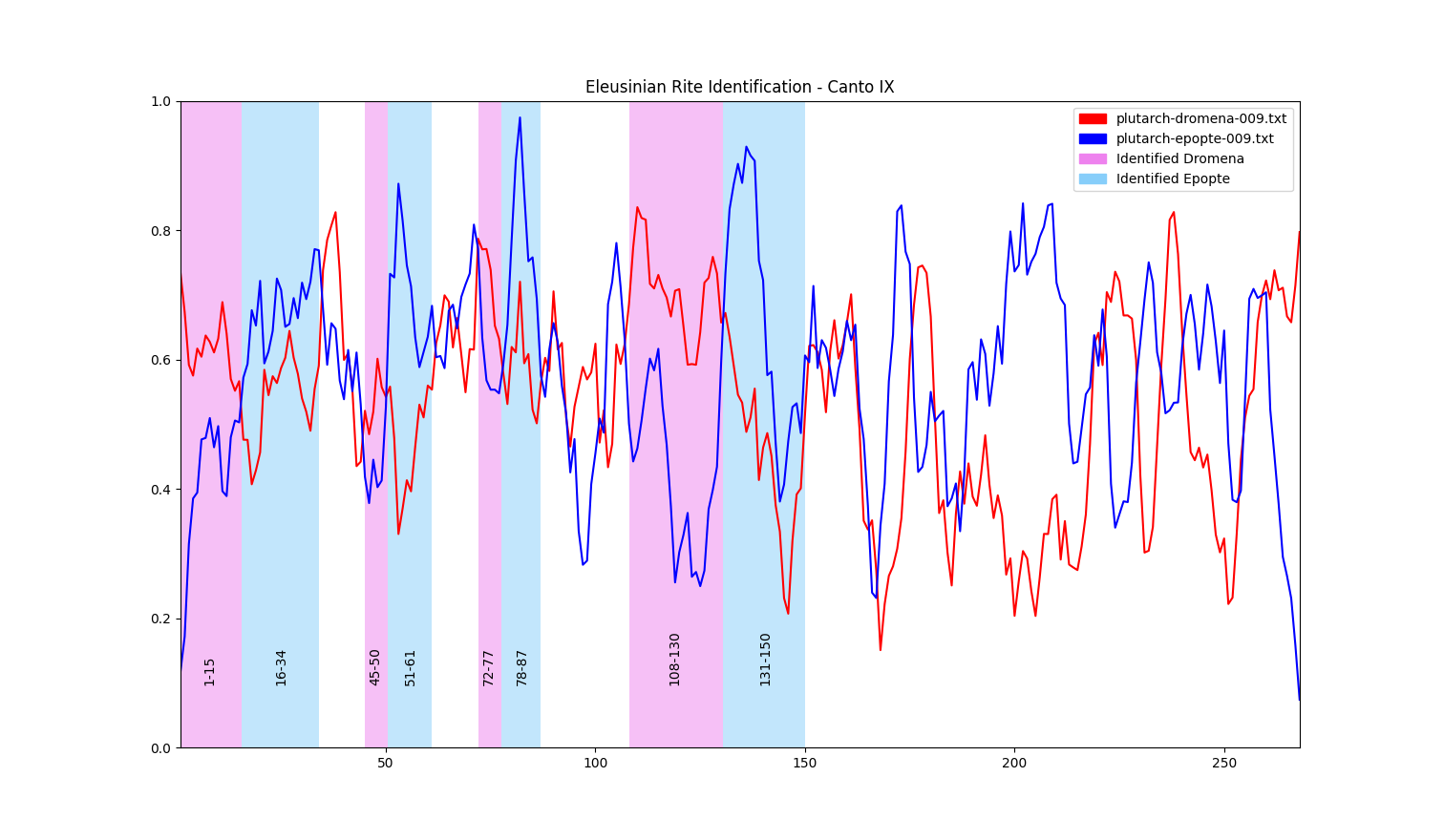
Now have a look at the opening 28 lines of Pound’s Canto IX.

There seem to be 14 lines of struggle followed by 14 lines of success. We see parallels in Pound’s and Plutarch’s language, for example where Plutarch uses ‘mud’ Pound uses ‘marsh’. The following table shows how Pound might have implemented Plutarch’s account.
| Plutarch | Pound |
|---|---|
| chance directions | floundered |
| difficult detours |
came in after three days floods rose fought in the snows... |
| terror |
they trapped him hounds / dogs ambush |
| shivering | stood in the water up to his neck |
| voices echo and figures dance |
fiesta lists... palisades tourneys |
| moving about without restraint |
talk down the anti-Hellene heir male to the seignor sold off small castles built... to his plan |
| a crown on his head |
the Emperor... knighted us Capitan nothing but the victory |
| mud | marsh |
We can also see a reflection in lines 14-15 and lines 27-28. In both instances the character, Sigismundo, gets into a fight. In the first he nearly dies, and in the second he wins (decisively). Lines 14 and 15 are interesting to us because they mark the end of the dromena. The epopte arrives suddenly at line 16 and we might wonder why. If we turn again to Plutarch we see,
those who are not initiated..., because of fear of death, remain among evils from failure to believe in the joy of the beyond.
Line 27 (concluding the epopte) says “and he fought like ten devils,” which suggests Sigismundo is not afraid of death. When compared to the dromena’s conclusion, “and that was nearly the end of him.” we notice Pound’s suggestion that a near-death experience has altered Sigismundo’s fortune. The near-death experience is the last of Sigismundo’s struggles; after it we see success. Pound doesn’t attempt to psychologically analyse the near-death experience (grace of the Modern method), but it is placed as an Eleusinian initiator. Although not in Plutarch, the near-death experience is elsewhere associated with initiation in the Eleusinian Rites, and traces of it as initiator can too be found in popular culture today.
The drive behind this experiment is to discover whether this form of the Eleusinian Rites is used as a vessel for other initiators. Does Pound present any other initiators, does he use this quote from Plutarch twice, or is this the only instance with only the suggestion of the near-death experience? Our premise is: If we can build a program to identify our control, it might be able to make further identifications.
Return to Theory
We should notice Pound’s manipulation of chronology. If we look at The Cantos Project for Canto IX, we can see that the floods, the snows, the hailstorm all happened from 1440-1444. The street fight happened in 1431, and the knighting happened in 1433. Regarding questions around form in Fugue and Fresco, it seems Pound composes to form instead of historical chronology, and will change chronology to suit form.
Form also has purpose here. At the least, it reiterates the Eleusinian Rites and the ability of a near-death experience to change a life. But importantly, it also shows that Sigismundo is initiated, and this is part of Pound pedestalling Sigismundo, marking him as a hero. I find the E.R. as a device more convincing than the beneficent speech of Canto VIII.
Identifying Canto IX
The BERT model we saw earlier only measures POSITIVE and NEGATIVE, which is not enough to discover Pound’s use of Plutarch. What we really want to do is to measure the Canto using language from Plutarch, and have it successfully match the regions of dromena and epopte.
The next best model after BERT is one with more labels available. For example, Emotion English DistilRoBERTa-base provides us with anger, disgust, fear, joy, neutral, sadness, surprise. We can see that these emotions might provide us with an insight closer to that of the Eleusinian Rites, but we should be even more faithful to what we are looking for.
So we turn to zeroshot classification. Zeroshot classification extends a text classification model’s capabilities by being willing to use classes (labels) it has no experience with. For a more in-depth understanding I recommend this video. Effectively, a zeroshot classification model allows us to define our own labels. Hence we can represent Plutarch’s account like this:

I have introduced lost to dromena as an extension of chance directions, and introduced freedom and political ability to epopte as extensions to moving about without restraint.
We choose a zeroshot classification model (bart-large-mnli) and classify a line of our Canto as before.
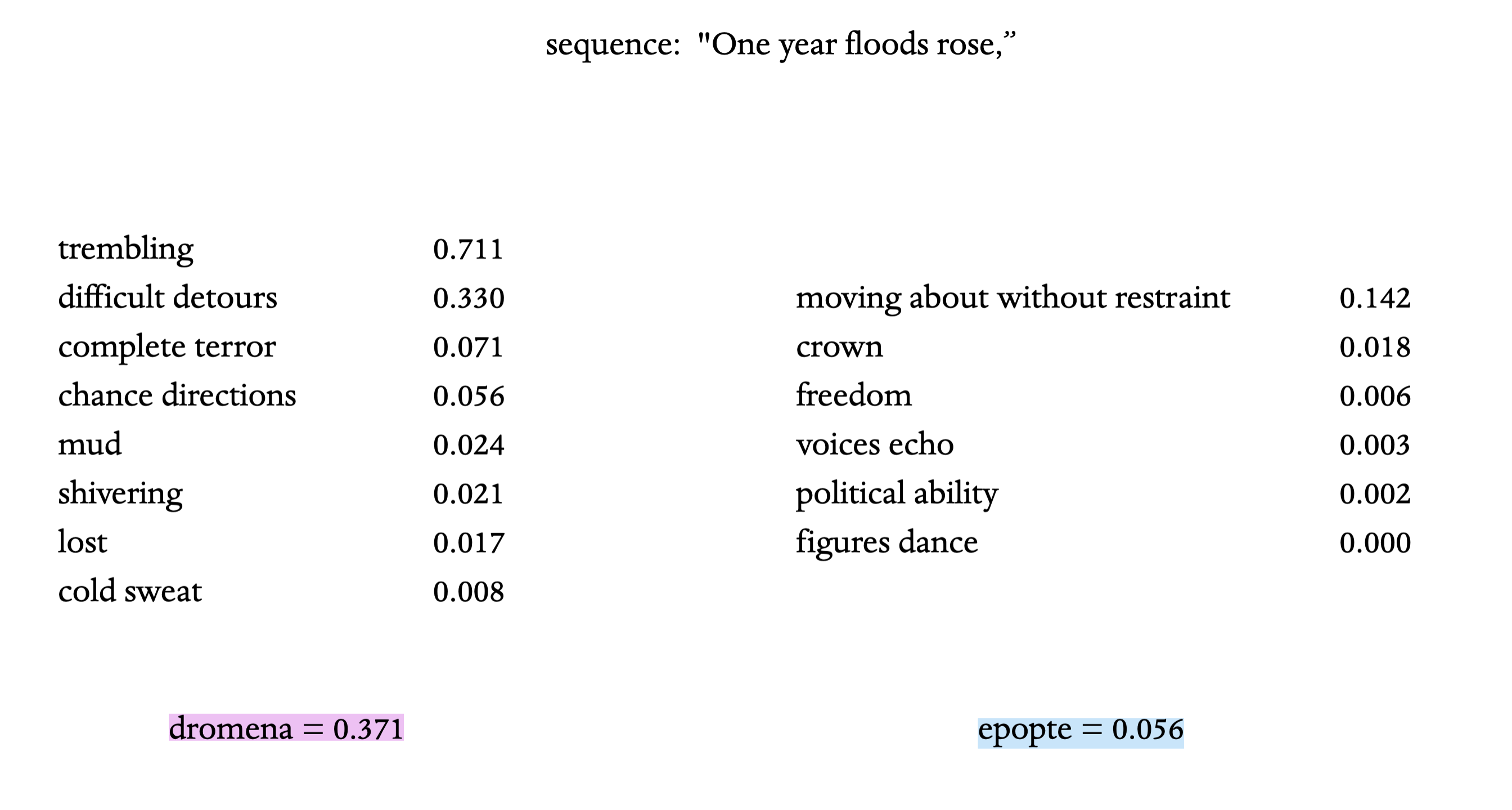
We are now comparing Canto IX to Plutarch’s account of the Rites. Because we are searching for measurements of dromena and epopte we would like to gain one number for each. Therefore I applied a rather brutal algorithm, taking the mean of the top 3 scores for each. Dromena (0.371) is greater than epopte (0.056) for this line which is a promising result; we expect the first 14 lines to be dromenic. When we pass in the whole Canto and plot the scores, we get the following graph:
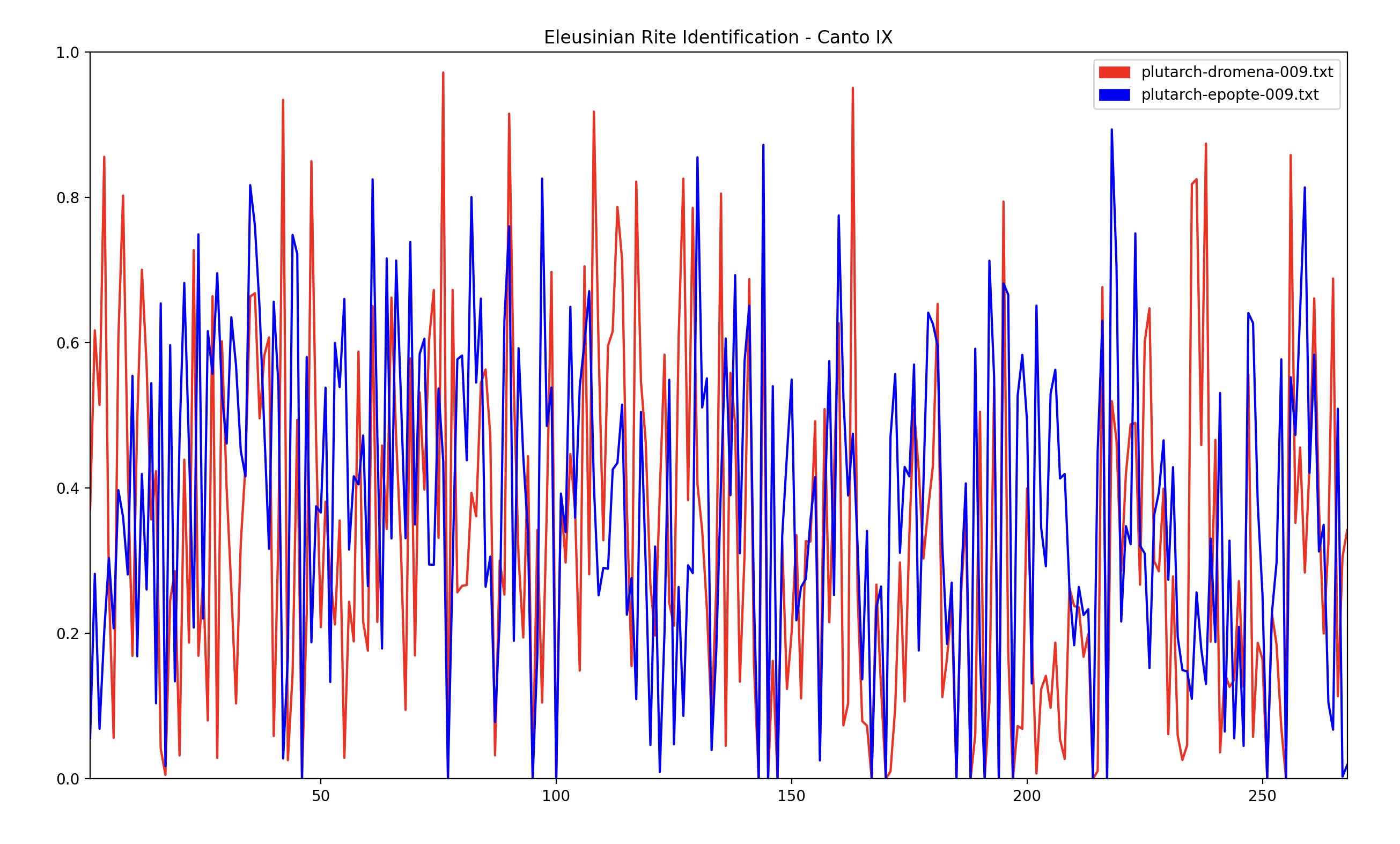
This graph is very noisy. We could plot dromena and epopte individually to improve legibility:
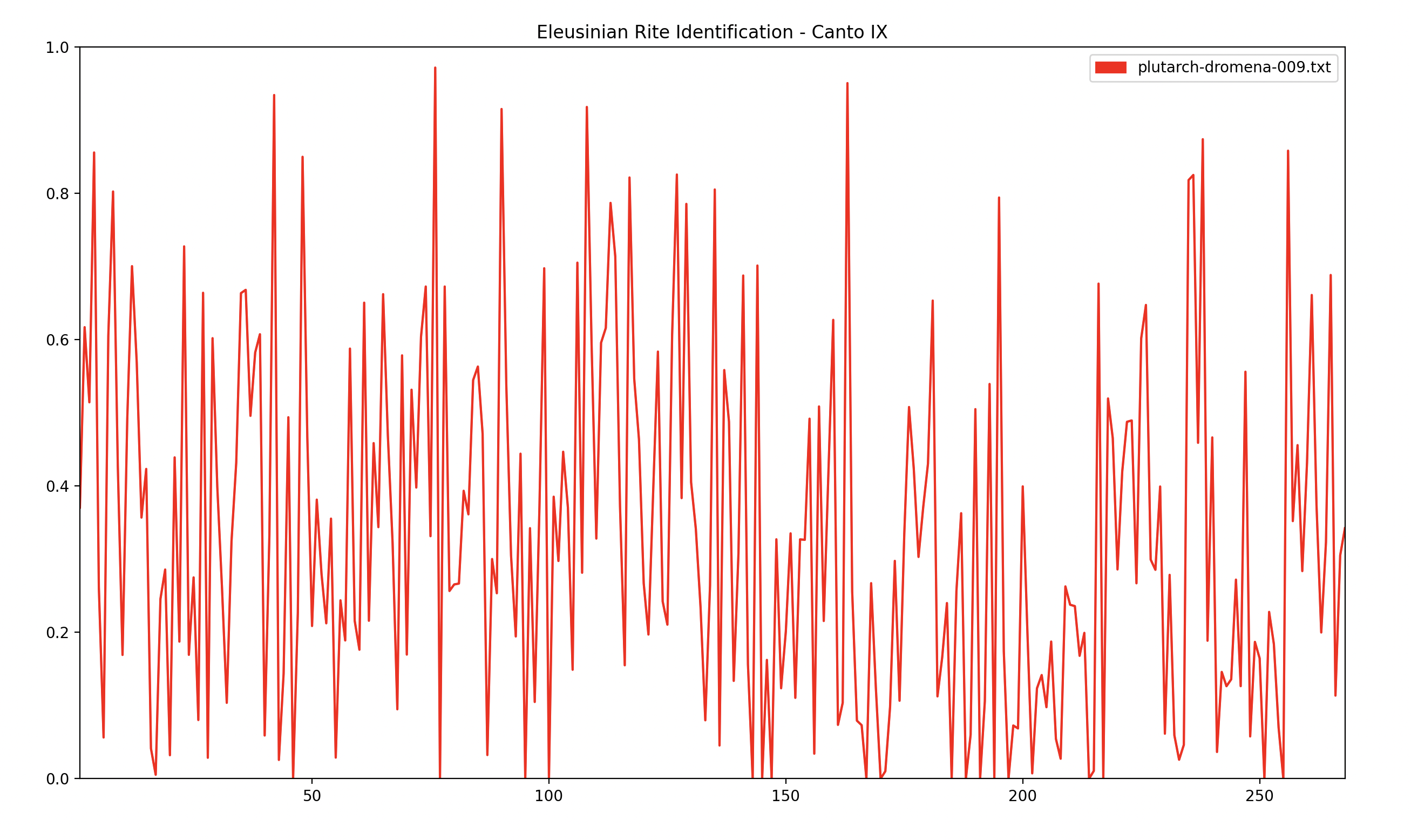
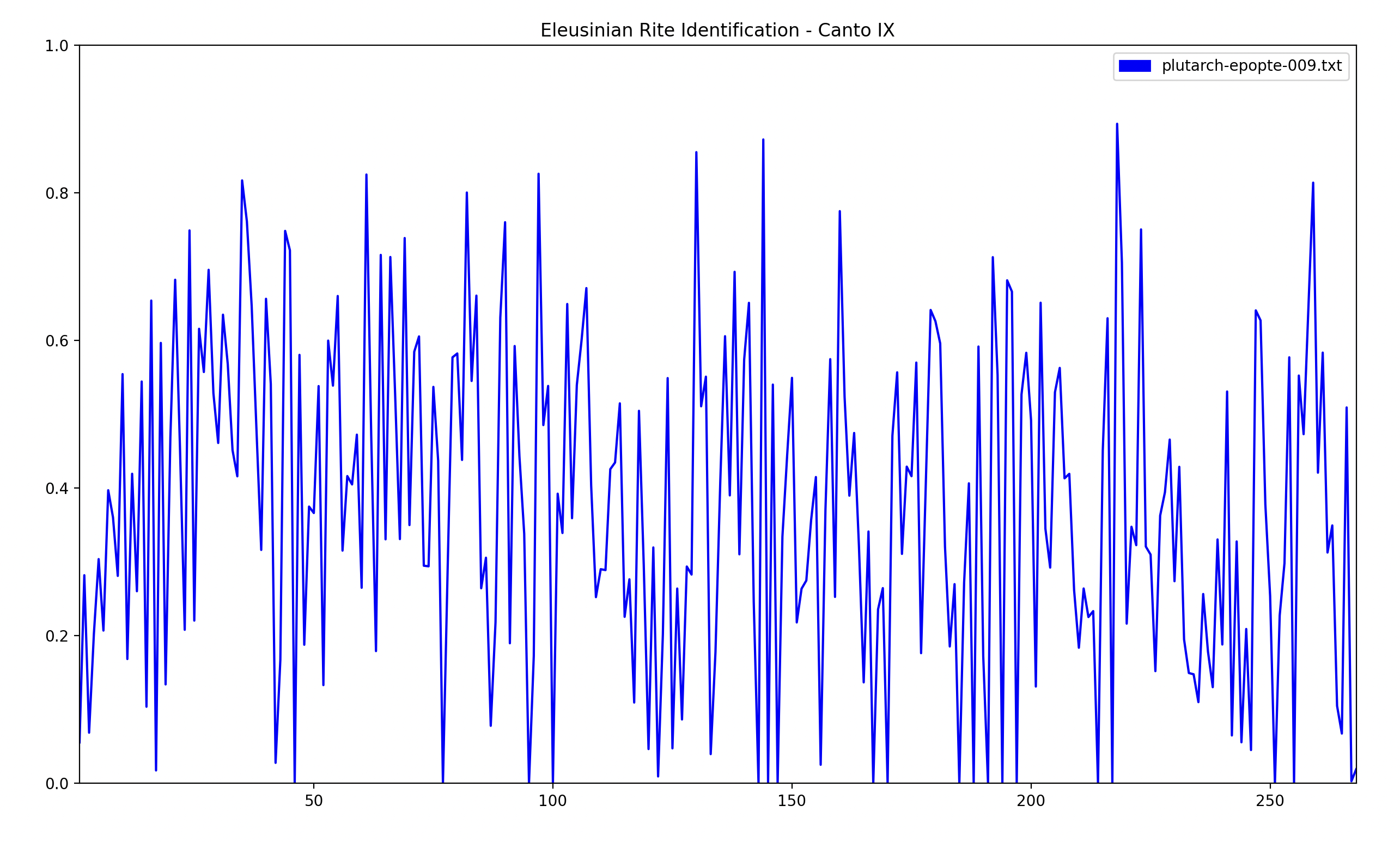
However the extreme movement between readings is going to make region identification very difficult. Instead of focusing on individual measurements (the possible improvements that can be made there are extensive), I decided to approach this from an engineer’s point of view and apply a signal smoothing algorithm, namely SavGol.
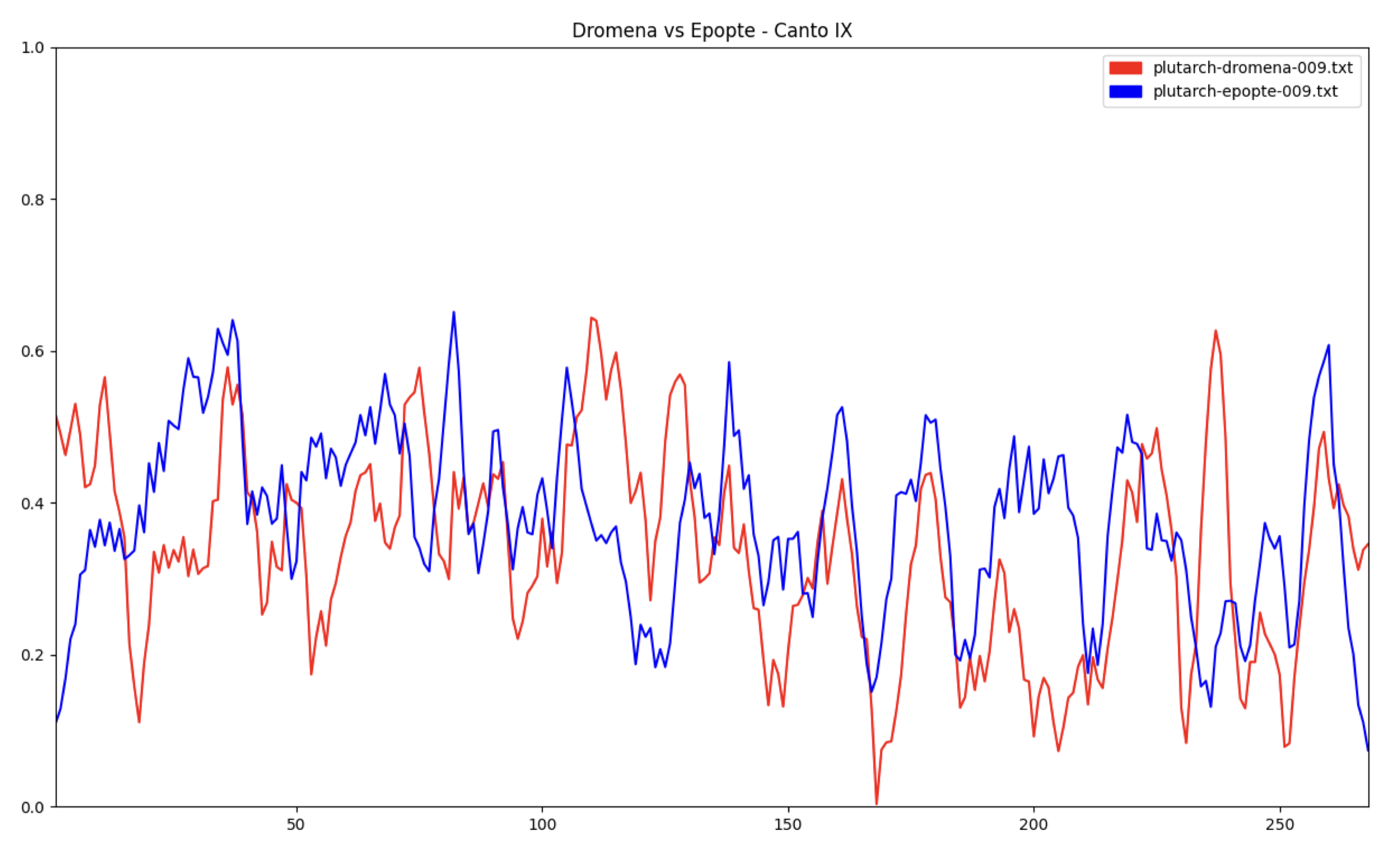
This graph is much more legible. We can even see our form at the beginning of the Canto. However it is important to consider what data we might have just lost, and what justifications we can offer ourselves.
We have lost the chance to read any inversion of dromena/epopte line to line. Our smoothing algorithm would probably produce a shallow curve, even if Pound was being extreme. If we were seeking such fine-grained movements in The Cantos, we would need to strongly consider removing any smoothing. However we have not yet done enough work inspecting and improving our per-line measurements. We do not know whether our measurements for each line are very accurate, and there is a huge scope for improvement here.
What we are doing is seeking regions; 14 lines of dromena followed by 14 lines of epopte. Therefore we can expect some clustering in our data. Since we are measuring Cantos one line at a time (other methods are up for discussion), our readings have no notion of region or clustering. Therefore a smoothing algorithm takes our theoretical intention to find regions into account. It finds a curve that suits the general movement of a noisy signal, and is acceptable at this early stage.
Identifying Regions
Given the above, smoothed graph, all that’s left for us to do to satisfy our control is to identify regions of dromena and epopte. This basic algorithm was sufficient.
def get_dynamic_eleusis_regions(eleusis_scores, min_length=5):
eleusis_regions = []
counting = False
dromenic = True
i = 0
while i in range(0, len(eleusis_scores)):
score = eleusis_scores[i]
if not counting:
start_dromena = i
if score > 0 and dromenic:
counting = True
elif score <= 0 and dromenic and counting:
# From dromena to epopte
end_dromena = i - 1
start_epopte = i
dromenic = False
elif score > 0 and not dromenic and counting:
# From epopte to dromena
end_epopte = i - 1
dromena_length = end_dromena - start_dromena
epopte_length = end_epopte - start_epopte
if dromena_length >= min_length and epopte_length >= min_length:
eleusis_regions.append(
((start_dromena, end_dromena), (start_epopte, end_epopte))
)
counting = False
dromenic = True
i += 1
return eleusis_regions
The algorithm looks for a minimum of 5 lines where dromena is greater than epopte followed by a minimum of 5 lines where epopte it greater than dromena. When run on the graph for Canto IX we get the following hits:
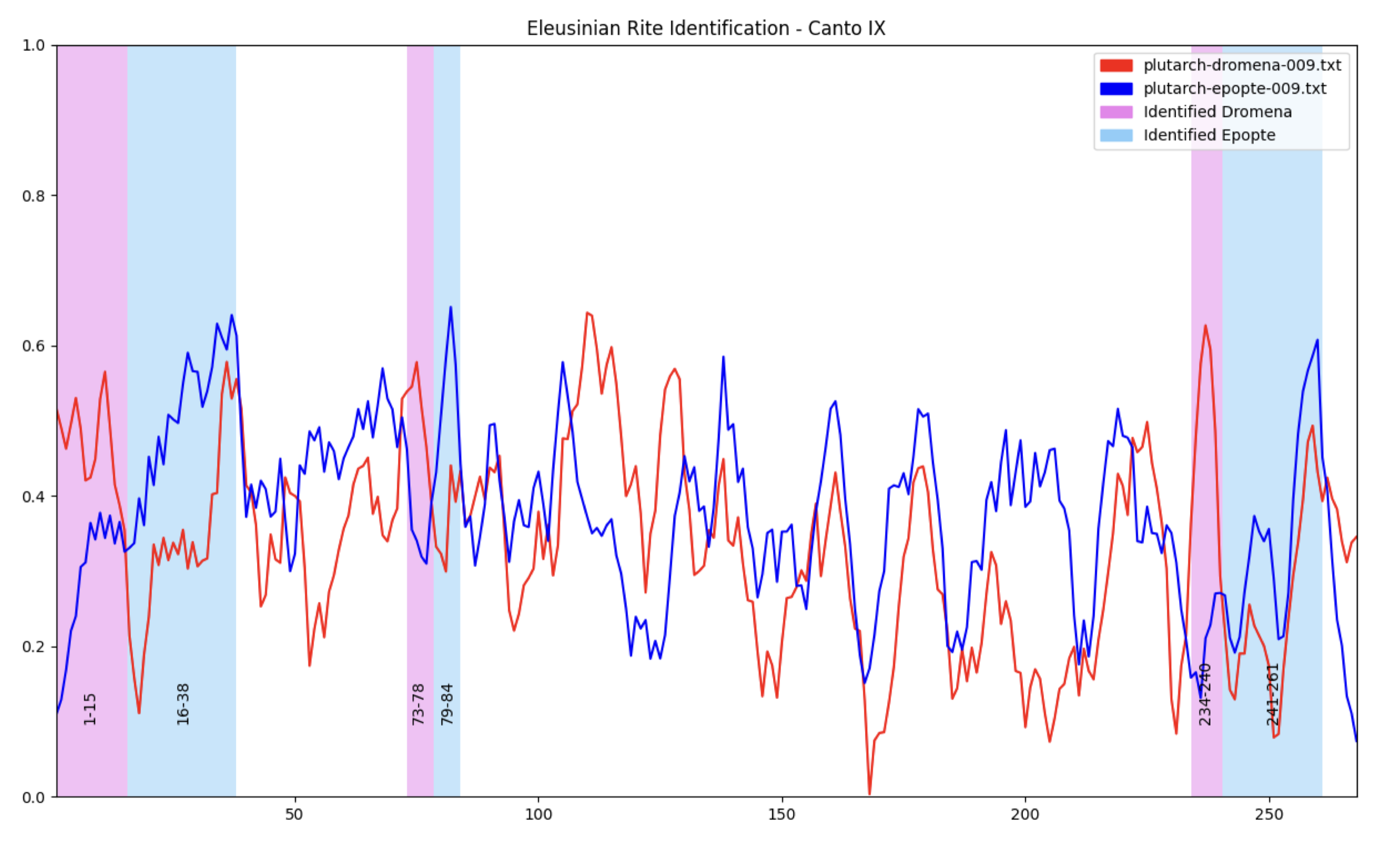
There is a trade-off in this form identification algorithm. Based on our control we could have chosen the min-length for each region to be 14 lines. Our control would have been satisfied, but there would have been only two other regions identified:
- Canto XVIII: δ = 72-87, ε = 88-102
- Canto XXII: δ = 17-36, ε = 37-63
At this early stage, however, we might prefer to be more inclusive, more open to potential readings before refining our results. Therefore I set the min-length to 5, as can be seen in the code.
Inspecting Graphs
56 regions were identified by this experiment. However, before we consider regions, the line graphs of this experiment presented obvious flaws.
In Canto V, there is an example of an identified region whose dromena and epopte movements do not fit our expectations. Epopte has remained fairly constant while dromena has fallen. We would like to see epopte rise as dromena falls. Therefore our region identification algorithm does not identify based on our real criteria: the fall of dromena and the rise of epopte. We could do this using differentials.
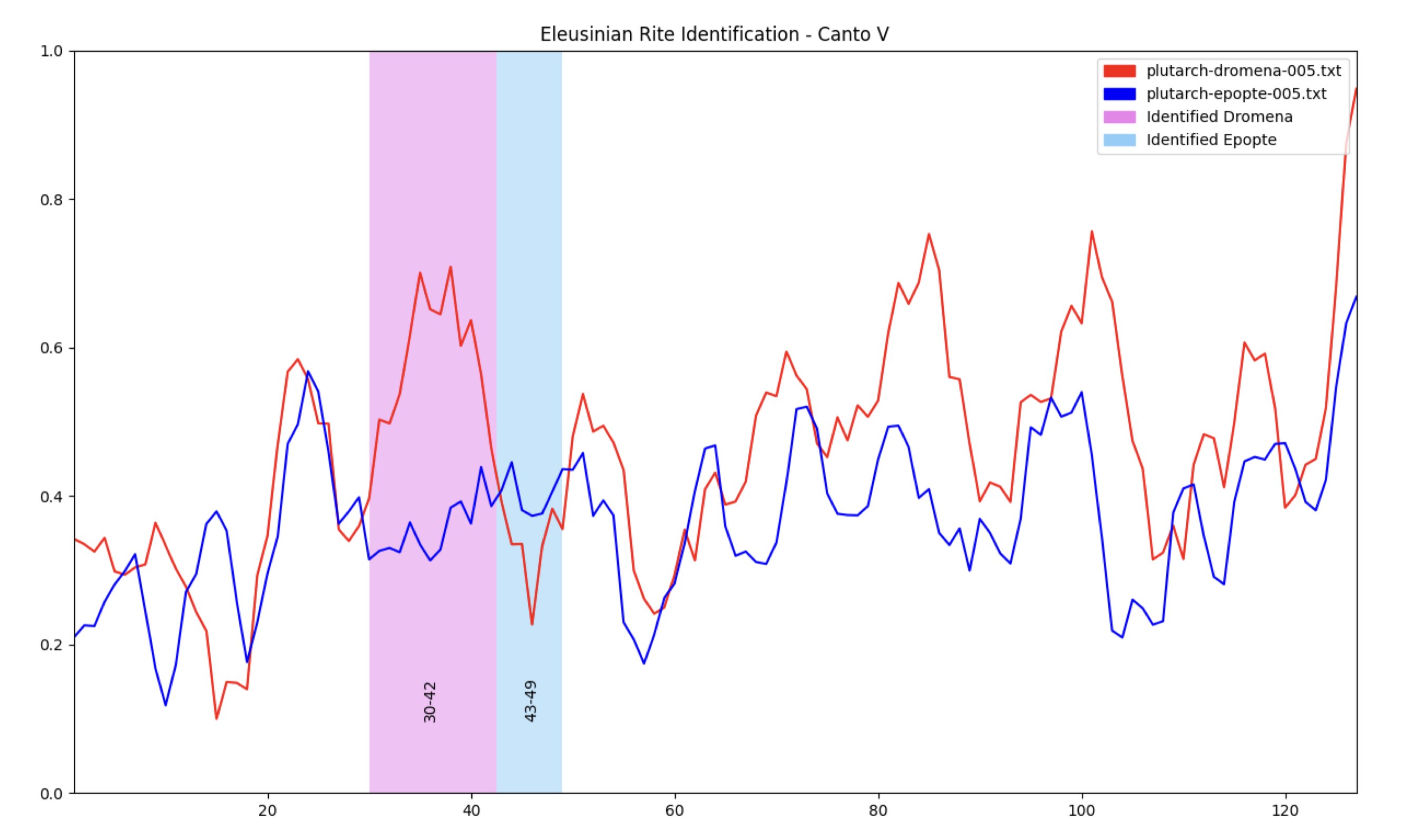
Another problem visible in the above graph is more obvious in the graph for Canto V:
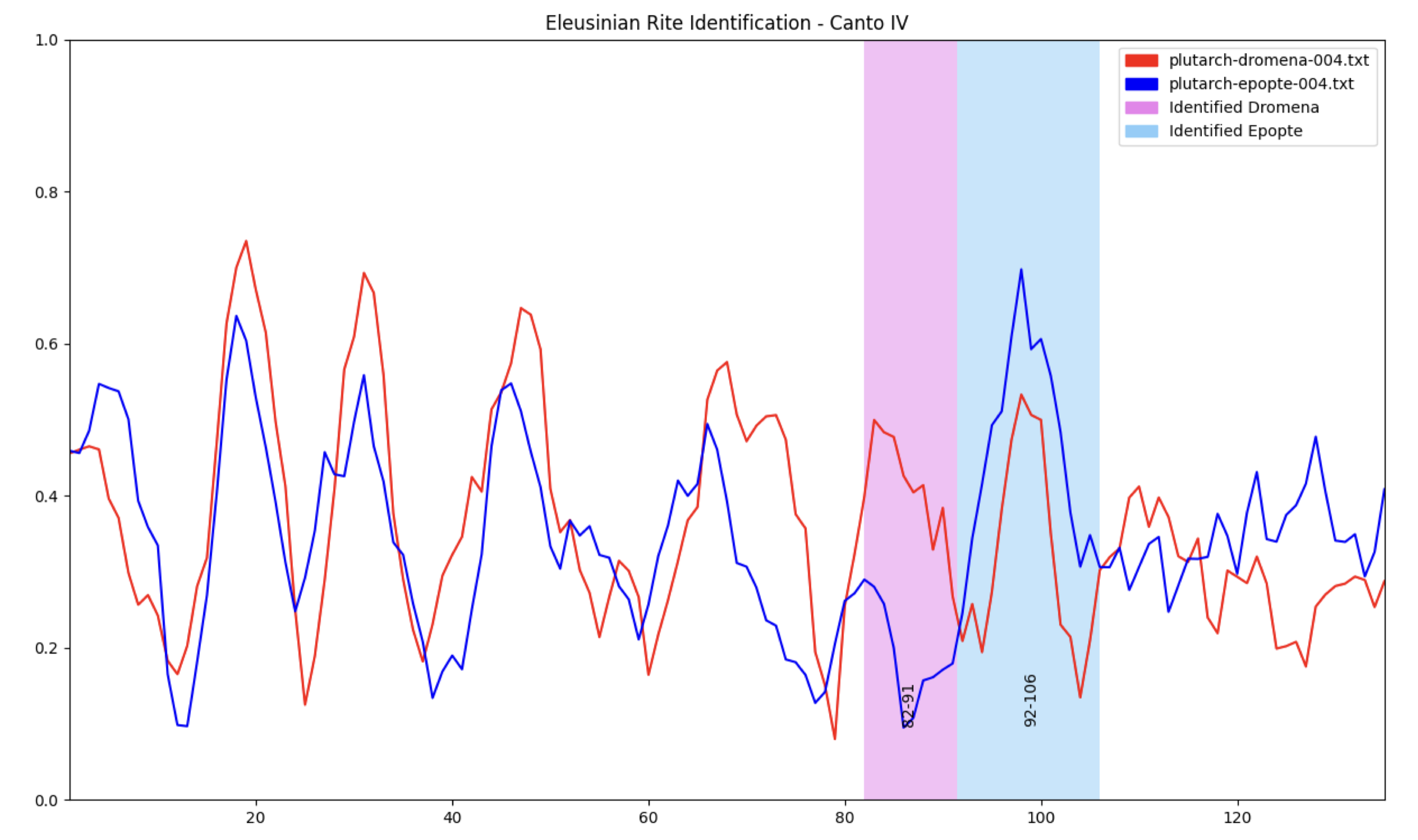
The lines for dromena and epopte are too similar. There are some possible reasons for this.
Firstly, it could be that our labels overlap. Or more specifically, that the zeroshot classifier is treating our labels too similarly (they share similar vectors).
Secondly, it is possible that our taking the average of the top 3 scores is destroying the data. When we inspect our per-line measurements, we notice that there is always at least one label in the top 3 that has a very low score. Not only does this reduce our average significantly, but it might have some bearing on restricting the movement of the graph.
Extending Labels
Extending the set of classification labels is a very easy change to make. We are hoping for two things: firstly that the new set of labels identify the control in Canto IX, and secondly that our lines for dromena and epopte are more often inversions of each other. Because we are working off our control, I have extended the labels using Pound’s language from the first 28 lines of Canto IX alongside some of his implications.

When we measure Canto IX using the extended set of labels we get the following graph:
Our control is identified, so we can continue.
The graph for Canto V no longer has dromena and epopte lines following each other.
Also, while in the first attempt our scores averaged about 0.4, our average score here is closer to 0.6. This is certainly in part related to having more higher scoring labels; our average of the top 3 is not dragged down. Yet the wide range of scores show that the zeroshot classifier is just as willing to score low on all labels as it is high. The increased average might give us more confidence in our labels.
Results
At the bottom of this page is a box where you can input a canto number (1-30) and see the graph and my notes for each Canto.
A total of 52 regions were identified. Most were not instances of the E.R. A few appeared promising, and I would recommend starting at Canto XX, which has 2 good regions. Apart from that, there were a number of improvements suggested by this experiment, which are:
- Improve the region identification algorithm. Regions are identified when, for example, dromena falls from high to low but epopte stays flat.
- Improve our labels for dromena & epopte. Our labels are focused around Canto IX and Plutarch, but in Chapter 2 Davis makes suggestions of dromena and epopte based on other metrics.
- Approach Cantos per-stanza. We currently score blank lines as 0 for dromena and epopte, yet treat our data as continuous. This is a mishandling of Pound’s verse arrangement. Furthermore, we also measure Cantos per-line while Pound’s sentiment might spill over two lines or change mid-line. I have attempted, on the side, to parse Cantos as sentences using ChatGPT, and might publish those results. However I think per-stanza measurements would be a better next step.
- Utilise annotations to inform the classifier. This involves providing English translations for classifiers trained on English. (There is a momentary loss of data in that Pound using non-English language is significant in itself, but the goal outweighs this subtlety for now.) This involves source information. The scope of new features here is very large.
Finally, a quick note that AI has only been used as a tool for study. I have chosen a very simple AI for this investigation. The benefit is that in the meantime a digital platform (poundian.com) has built up around the experiment, and the digital approach will at some point hopefully open out into the use of more powerful models.